A Complete Guide to OpenTelemetry


By
Pralav Dessai

By
Harold Lim
Published on
Oct 11, 2024
Table of Contents
OpenTelemetry is a powerful framework for monitoring software systems. It helps you collect and process telemetry data like logs, metrics, and traces. We created this guide to take you through key aspects of deploying and configuring OpenTelemetry, including deployment modes, memory buffers, resource decorators, semantic conventions, SDK deployment, sampling methods, and pipeline transformers.
Choosing the Right OpenTelemetry Deployment Mode: Daemon vs. Gateway
In daemon mode, the OpenTelemetry Collector runs as a background service on the same host or container as the application it monitors, collecting, processing, and exporting telemetry data locally before sending it to your observability platform.
In contrast, gateway mode involves running the OpenTelemetry Collector as a centralized service or set of services that collect, process, and export telemetry data from multiple sources to a centralized backend.
Depending on your observability needs and constraints, you can choose between daemon and gateway deployment modes. Here’s a brief comparison:
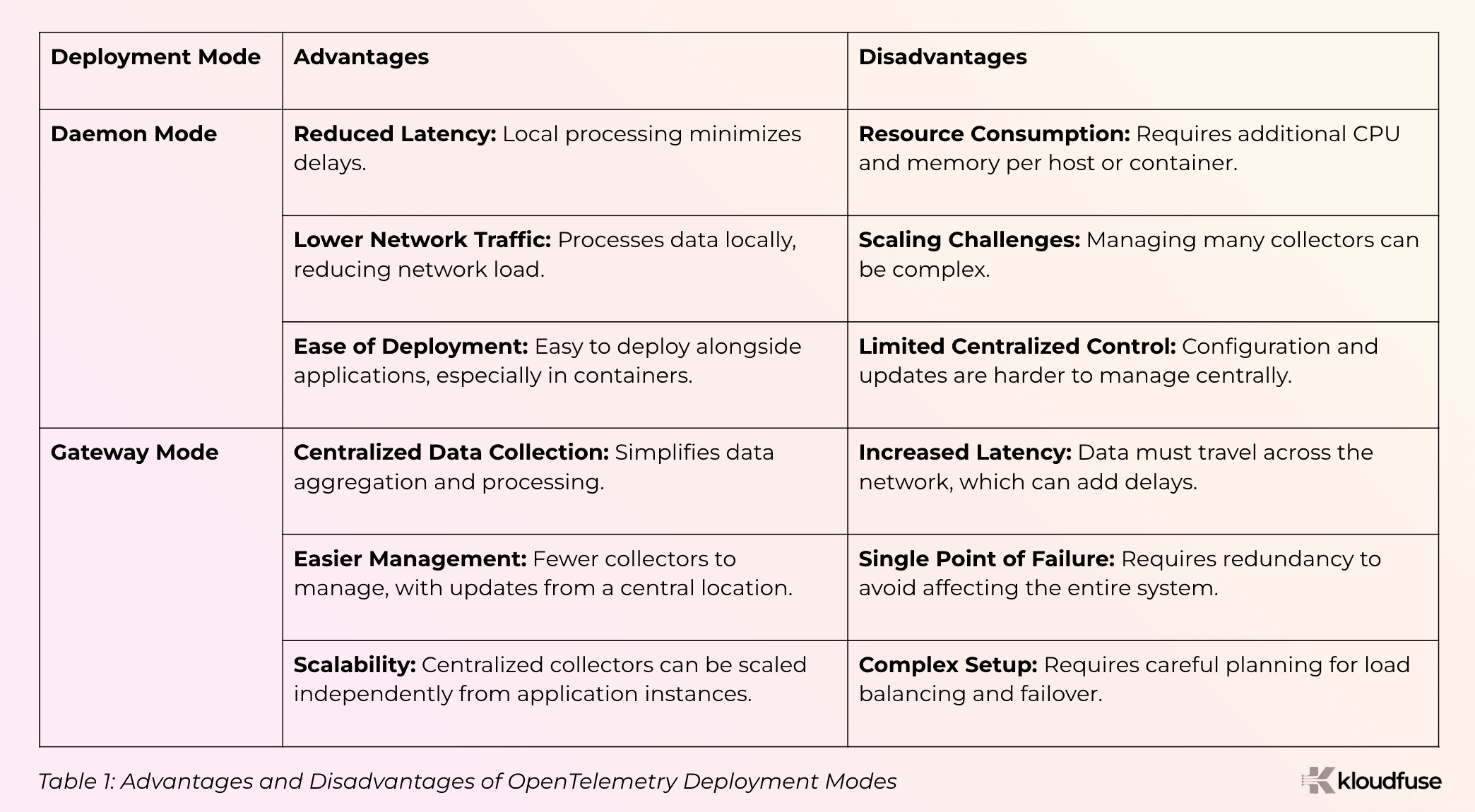
By evaluating these factors, you can choose the deployment mode that best aligns with your architecture, scaling needs, and operational preferences.
Optimizing Memory Buffers in OpenTelemetry
Memory buffers in the OpenTelemetry Collector temporarily hold data before it’s processed or sent to your observability platform. Setting these buffers correctly is important to manage data flow and prevent performance issues, especially during spikes in data volume.
Best Practices in Setting up Memory Buffers:
Size Buffers Based on Data Volumes: Analyze the volume and patterns of telemetry data generated by your applications and set appropriate buffer sizes that can handle peak loads without data loss.
Balance Memory Use: Larger buffers can hold more data but use more memory. Avoid setting buffers too large, as it can slow down your system.
Reduce Latency: For real-time data, use smaller buffers to ensure quick processing and exporting of data.
Separate Buffers for Different Data Types: Use different buffers for metrics, logs, and traces. For example, use a 5 MB buffer for metrics (which come in small, frequent bursts) and a 10 MB buffer for traces (which are larger but less frequent).
Monitor and Adjust: Keep an eye on buffer levels and latency. If buffers are often full or data processing is slow, consider increasing buffer sizes or tweaking data collection settings.
Adding Context to Your Telemetry Data with Resource Decorators
Resource decorators add metadata to your telemetry data, like the hostname, application name, or environment (e.g., production or staging). This extra context helps you better understand and analyze your data, making it easier to diagnose issues and improve your system’s performance.
Best Practices for Implementing Resource Decorators in OpenTelemetry:
Define Clear Metadata: Choose essential details like environment (e.g., production, staging), application name, and version. Make sure this metadata is consistent across all services for better analysis.
Use Environment Variables: Set metadata using environment variables instead of hardcoding values. For example, use ${SERVICE_NAME} and ${ENVIRONMENT} to dynamically set metadata attributes based on where your application is running.
Document and Communicate: Document the resource attributes being used, their purpose, and how they should be configured. This helps maintain consistency and makes it easier for new team members to understand.
Semantic Conventions: Creating Unified Observability
Semantic conventions help keep your telemetry data consistent and meaningful, making it easier to use with different systems and tools. Here’s why they’re important:
Standardization: Using these conventions ensures that the telemetry data is understandable and consistent with other systems that follow the same conventions.
Interoperability: By adhering to these conventions, different monitoring and observability tools can work together more effectively, as they understand the same data structures and meanings. Additionally, tools that visualize or analyze traces can use these attributes to provide insights without requiring custom parsing or mapping.
Analysis and Troubleshooting: Consistent naming and attributes enable easier filtering, grouping, and analysis of traces, making it simpler to diagnose performance issues or errors.
Example: For tracking user login events, use a trace span named "user-login" with attributes like user.id, login.success, and login.time.
If a user with ID "789" logs in successfully at "2024-09-17T10:00:00Z", you would set:
user.id: 789
login.success: true
login.time: 2024-09-17T10:00:00Z
This standardization makes it easy to monitor and analyze login events across different systems.
Deploying OpenTelemetry SDKs: Key Tips for Success
Deploying OpenTelemetry (OTel) SDKs can greatly enhance your application's observability, but it's important to get the setup right. Here are some simple tips to help you deploy OTel SDKs effectively:
Check Language Support and Compatibility
Make sure the OTel SDK supports your programming languages (like Java, Python, JavaScript, C++, or Go) and works with your library versions. For instance, if you use Java 11, make sure the SDK is compatible.Choose Your Instrumentation Type
Automatic Instrumentation: The OTel SDK or agent automatically captures telemetry data without requiring changes to the application code. For example, the OpenTelemetry Java SDK can automatically instrument Java applications.
Manual Instrumentation: You need to add code to your application to collect metrics, traces, and logs. For example, you might need to manually add instrumentation to specific functions or classes in a C++ or GO application.Configure Exporters
Configure exporters to ensure that your telemetry data (traces, metrics, logs) is sent to the observability backend of your choice, such as Kloudfuse, Jaeger, or Prometheus.By following these tips, you'll set yourself up for success with OpenTelemetry SDKs and gain valuable insights into your applications.
Sampling in OpenTelemetry: Comparing Tail Sampling vs. Head Sampling
Sampling is a way to manage large amounts of telemetry data by selectively capturing a representative subset of trace data. There are two main methods: head sampling and tail sampling.
Head sampling decides whether to collect a trace at the start, based on set rules. It’s easier to use and has less impact on performance, but it might miss important traces if the initial rules aren't good enough.
Tail sampling waits until the trace is finished to decide if it should be kept, looking at all the data. This method is more flexible and can capture more complete information, but it requires more resources and is harder to implement.

Pipeline Transformers: Data Enrichment, Filtering, and Compliance
Telemetry data often has a lot of noise, making it difficult to identify useful information. To filter out this noise and gain meaningful insights, OpenTelemetry offers a Pipeline Transformer that allows you to modify telemetry data before it is sent to your observability solution.
Here are some key areas why you might want to use a transformer in your OpenTelemetry pipeline:
Data Enrichment:
Data enrichment allows you to add context to your telemetry.
Data enrichment lets you add context to your telemetry. For instance, if you want to track the application version in both development and production, you can include it as an attribute. You can do this with a simple configuration: upsert: { "application.version": "1.2.3" }. This attaches the version "1.2.3" to each span.Data Filtering:
Transformers allow you to filter out unnecessary or sensitive information. For example, using processors: filter: metrics: - metric_names: ["*"] condition: "metric_value > 10000" filters out metrics with values over 10,000, while processors: filter: traces: - span_duration: "10s" condition: "duration > 10s" removes spans longer than 10 seconds.Data Transformation:
You might need to reformat or aggregate data to match the schema or requirements of different backends. For example, you may want to convert all Unix timestamps to ISO 8601 format with processors: attributes: actions: - action: update key: "start_time" value: "timestamp_to_iso8601(start_time)".Anonymization and Redaction:
To ensure compliance with privacy regulations, transformers can be used to anonymize or redact sensitive information before it leaves your environment. For instance, sensitive data like user IDs can be redacted with processors: attributes: actions: - action: redact key: "user_id" value: "[REDACTED]".
As we’ve explored in this guide, OpenTelemetry provides a comprehensive framework for monitoring and observability, enabling you to effectively collect and analyze telemetry data from your applications. By understanding the nuances of deployment modes, memory buffers, resource decorators, semantic conventions, and sampling techniques you can significantly enhance the insights gained from your telemetry data.
Happy monitoring!

